Navigation auf uzh.ch
Navigation auf uzh.ch
Since April 2019, I am working on my mobility project From parallel corpora to multilingual exercises - Making use of large text collections and crowdsourcing techniques for innovative autonomous language learning applications funded by the SNF, partly at Språkbanken in Gothenburg and partly at GR@ELin Barcelona.
I studied Computational Linguistics at the IMS in Stuttgart. During my studies I spent two years in Barcelona where I had the opportunity to participate in the PATExpert project at the TALN group and, later on, write my diploma thesis about dialogue interaction in role-playing video games.
Following my graduation, I led the development of digital cinema content logistics in an international firm (now Ymagis), resuming work that I had carried out for several years as student. From 2013 to 2017, I worked as PhD student in the SPARCLING project, investigating methods for assembling and querying large multiparallel corpora with a special focus on multilingual alignment.
Having learned programming in high school, I used to write small applications to support my own language acquisition (vocabulary and inflection) and later on continued developing language learning software with schoolmates, which brought us several prizes in the Jugend forscht competition. In 2017, I spent two months at Språkbanken in Gothenburg to learn about their approaches to corpus-based language learning applications.
Starting in fall semester 2014 (HS14), I have been giving the last lecture in the programming techniques for computational linguistics series (PCL III), in HS15 together with Peter Makarov and in HS16 with Fabio Rinaldi. This lecture is centered around designing and implementing interactive applications (in contrast to processing pipelines) with complex data structures. Another key aspect of the lecture is software development in teams employing version control.
In spring semester 2014 (FS14), Martin Volk and I held a research seminar about methods and tools for large parallel corpora.
I (co-)supervised and worked with these students:
My main interest are parallel and multiparallel corpora, and their exploitation for multilingual phraseology and CALL applications. As regards the topic of language learning, I have mostly worked together with Gerold Schneider.
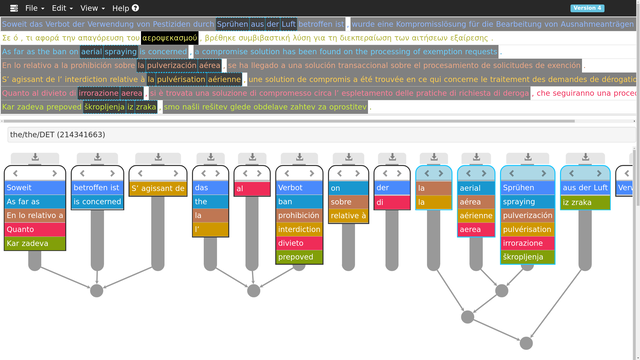
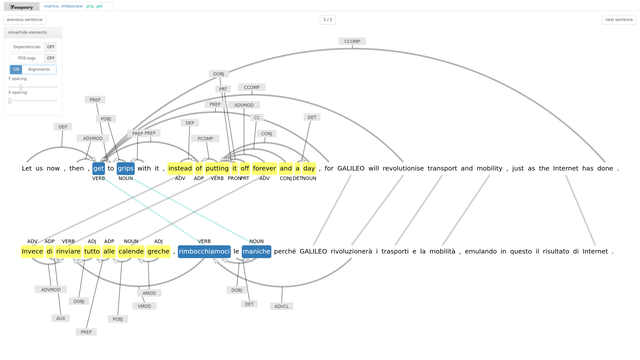
These applications require multiingual alignment on different levels, in particular alignment of units larger than single tokens (e.g. phrases), a problem I dealt with in my dissertation.
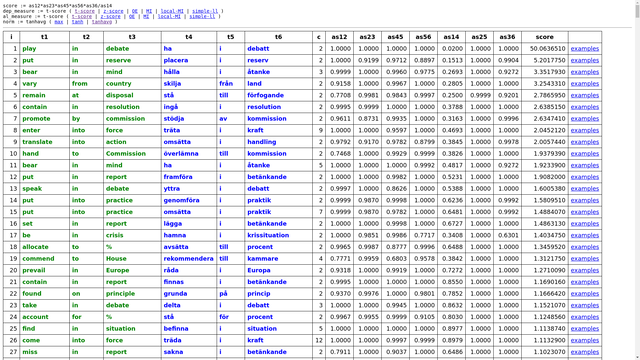
Other aspects include efficient corpus storage and query systems for multiparallel corpora and visualization of their results.
I previously have been working for several years as SysAdmin for Linux servers and DevOp for applications based on PostgreSQL. During my time at the Department of Computational Linguistics, I had the chance to build our new IT infrastructure from scratch, based on virtualization (Proxmox) and distributed services. The architecture of our infrastructure has proven useful for both development and providing services, that is, web applications and pure web services. Most of my skills in this area date back to my active time at Selfnet e.V. in Stuttgart.
During my studies, I used to regularly take language courses. Besides German and English, I speak Spanish (C1), French, Portuguese, Italian (B1), Catalan and Swedish (A2). I also took lessons in Russian, Polish, Czech, Turkish and Icelandic, but, up to now, I can merely read simple texts in these languages.
I enjoy garlic (like in Tzatziki or Gazpacho), volleyball (my previous team) and good movies (Uni-Film Stuttgart, Filmstelle Zürich, Texas cinema). My preferred red wines come from the Montsant region.
(see also thumbnails on the right)